A Federation model to support semantic SPARQL queries for Enterprise Data Governance
[data-governance sparql This post is an extract of the article “Federation model to support semantic SPARQL queries for Enterprise Data Governance” presented at IEEE 11th International Conference on Digital Information Management (ICDIM), Porto, 2016.
Data Governance strategies involve the convergence of multiple functionalities such as Data Quality, Data Management, Risk Management, and Policies definition and enforcement. The importance of Data Governance relies on its ability to understand how data flows across an organization, which constraints must be considered, along with the regulatory landscape, who is responsible for the data and who can use the data themselves. Once these issues have been clearly shaped, Data Governance aims at defining rules on the data model and the data itself.
Data Federation – the ability to seamlessly and transparently integrate data stored at different places – plays a crucial role in Data Governance and is usually seen as a specialization of Data integration systems, where data storage abandons the idea of single centralized physical endpoints, and leverage fully integrated, fully distributed models.
The governance of large distributed organizations poses non trivial challenges in discovering, aggregating, and managing data in heterogeneous forms and from different and distributed sources, both within and outside the organization boundaries. That produces governance models where data integration and organization knowledge is typically limited and with no flexibility. A typical example would be the case of the integration of ERP systems data with both traditional CRM/marketing analysis and with novel social media analysis systems to proactively influence enterprise production and operations, e.g., supply chain and stock management tuning as well as workforce optimization.
Semantic web principles, methodologies, and techniques have long proven to be semantic crucial in modeling and managing complex relationships between entities/data and to support interoperability, reasoning and inference/automation in coarse-grained, semi-structured, and heterogeneous data environments: in this field, the SPARQL protocol (based on the RDF specification) has become the de-facto standard to extract and manipulate information from distributed data sources on the web. Semantic Web has long emerged as the transformation of the World Wide Web in an environment where content (HTML pages, binary files, images/media content, and so on) are enriched with metadata that specify the semantic context of content itself. Metadata langaguages and formats (such as RDF and OWL) are primarily conceived to easily express information about content, and automatically perform semantic data query (e.g., via search engines), interpretation, and, more generally, to automatic aggregation and reasoning. Semantic Web takes cooperation between computers and humans one step further, and allows humans to leverage a more autonomous and intelligent machine support in the execution of the generic tasks.
A key element of the Semantic Web is W3C SPARQL, which is a query language for Resource Description Framework (RDF), and has long set itself as the de facto standard to perform semantic queries on content exposed on the Web. RDF describes the concepts and relationships about them through the introduction of triples (subject-predicate-object); triples that have some elements in common become parts of a knowledge graph. SPARQL helps navigating such knowledge graphs and searching for sub-graphs corresponding to the user’s request.
Semantic Web and SPARQL query language form a promising platform to support Data Governance and federation needs, and allow to build a connected network of information. Semantic Web standards and the SPARQL query language have long proven to be key in enabling open, autonomous, machine-driven content matching, and reasoning knowledge management infrastructures, through the infer of relationships and dependencies from heterogeneous sets of information pieces. However, SPARQL support for data federation, via the SERVICE construct, e.g. distributed data source integration and query, is still at an early stage and proves poorly suitable for large, real-world scenarios. SPARQL data federation limitations is mainly related to a priori knowledge of data models and actual data across all data sources involved; this becomes relevant in large complex scenarios where data sources are heterogeneous and can change frequently and at different paces from each other.
Data Federation is crucial in letting organizations easily and effectively shaping and supporting information flow across organization branches. Typical issues such as heterogeneity and distribution of data sources must be overcomed defining a viable and effective model and implementation to adopt Semantic Web methodologies and the SPARQL implementation.
The key principles in defining that solution are:
- Openness: data federation and integration in large organizations typically means integrating data sources from heterogeneous (both custom and third party) systems; avoiding vendor lock-in and preserving openness and portability is key in defining a sustainable, long-term data federation strategy for any organization
- Lightweightness: the proposed solution should pose limited to no overhead on running systems, so as to minimize the impact of Data Federation on large organizations with complex, highly distributed data sources
- Autonomy and ease of use: the proposed solution should be able to cope with uncertainty, and to autonomously discover relationships among federated data even in case o partial a priori data model and network knowledge.
A Federation Web Service solution is proposed.
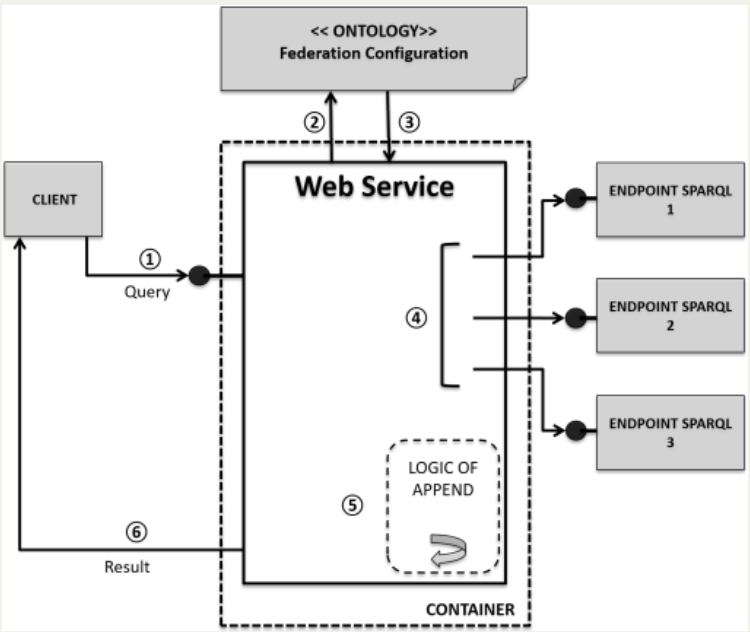
It is based on creating a Web Service which realizes all the functions related to federation. The Web Service approach makes this solution portable to any semantic platform implementation, thus fostering openness and interoperability. Furthermore, to facilitate the management of large semantic data networks, it is necessary the development of a specific lightweight Network Federation Ontology that facilitates the definition and navigation of network topology, to map information sources across organizations, so as to adddress current SPARQL limitations in terms of a priori network knowledge. The Federation Web Service relies on such an ontology to transparently determine which nodes and endpoints should be involved, thus facilitating the definition of federated semantic queries.
Thus, the logical flow of the Federation Web Service is as follows:
- Federation resolution: thanks to the Federation Ontology, the Federation Web Service determines the actual endpoints involved in the federation, inferring network endpoints upon with to perform queries
- Query execution: the Federation Web Service performs queries on all individual nodes involved in the federated query
- Result aggregation: the Federation Web Service aggregates the results obtained from single nodes and returns them to the caller. The aggregation techniques can be managed through the typical constructs of the SPARQL language, such as the UNION clause.
The proposed solution is a portable, non vendor-specific, semantic-based approach to overcome organization governance complexity and to mitigate/hide heterogeneity and distribution of data sources, through a reference architecture model and implementation that relies on a federation of SPARQL endpoints.