Adaptive Provisioning and Migration of Services in On-Premise Cloud
[cloud-computing observability migration This post is an extract of the article “Service State Migration for Elastic Provisioning of Telco Services in Mobile Cloud Networking”, presented at IEEE Transactions on Services Computing, 2018.
Nowadays cloud computing is a very well recognized technology that provides technical and economic advantages for the provisioning of telco service infrastructures, in particular towards all-IP next generation 5G networks. Cloud exploitation significantly lowers investment risks by potentially providing elasticity in service provisioning via flexible infrastructure management. Although, public cloud providers has become very popular and recognized in the field, there are many on-premise infrastructure, e.g. to provide telco services.
The solution has been adopted by the Mobile Cloud Networking (MCN) project, a large-scale EU project that had involved several leading 5G and cloud companies, research centres, and universities. MCN aims to enable European Telco industry to grow mobile cloud computing by provisioning quality-constrained, carrier-grade, and cloudified telco services in an efficient way. This goal is pursued via the creation of an ecosystem of service management mechanisms, tools, and frameworks for self-management, self-maintenance, on-premises design, and operations control functions.
In particular, it is challenging to determine how to achieve cost-effective elastic provisioning of telco services over heterogeneous and federated cloud providers, with the specific focus of supporting the extreme quality levels that are demanded by traditional, non-virtualized, and dedicated telco infrastructures. Thus, how to effectively and efficiently automate service state migration for coarse-grained telco service components is a central topic.
The architecture of the MCN project is shown in the following figure:
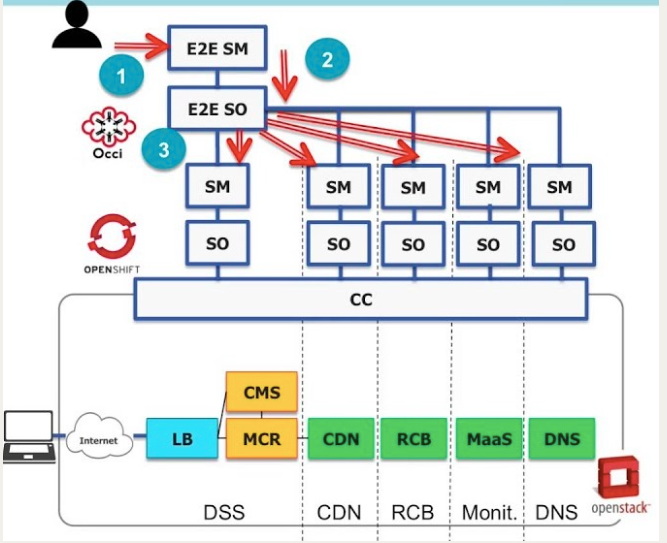
Within this context, one component inside the MCN project, the Rating-Charging-Billing (RCB) component is a key component that experienced an high traffic and busy workload in production to serve all the requests, leading towards a relevant performance degradation. This component is based on Cyclops, an open source tool that collects information for accounting and billing purposes taking as input the service consumption metrics, processes them, calculates the price to be charged to the user, and generates the invoice for payment.
In order to overcome the performance degradation, the service state is migrated anticipating state migration through traffic patterns prediction that allow to evaluate a component requiring very limited a-priori knowledge and by using Zabbix as the monitoring component. Zabbix is a software toolkit that provides an effective, scalable and reliable monitoring, with a wide range of monitoring performance indicators and metrics; it offers a distributed infrastructure where Zabbix agents collect data locally on behalf of a centralized Zabbix server and can report the data to the server. Based on the monitoring evaluation and prediction, the chosen migration approach is a general-purpose VM migration that uses the combination of two phases: pre-copy, which pushes most of the data to destination host before stopping and migrating the VM; post-copy, which pulls most of the data from source host after resuming VM at the destination host.
In this way, when the migration is triggered:
- a new VM is created to a different and less used host. OpenStack makes available the Heat service (Infrastructure as Code component of OpenStack) to create VM replicas
- (pre-copy) the VM state is moved to another newly created VM, similarly to the creation of staging-production VMs in a blue/green deployment scenario, by leveraging on the Heat template feature to start and manage the connection to the old instance and, thus, to the database migration
- the service is then switched on on the staging VM that becomes the new production VM and, vice versa, the production VM is switched off and no longer used
- (post-copy) the new VM receives the data collected while the new production VM was prepared and merge them with the existent ones.
The connection and management of the remote VMs has been done using the library Paramiko, a Python library for making SSH2 connections with both the client side and server side functionality and which has become popular because also used in Ansible tool.
Within the MCN scenario, the service state migration consist to migrate all the temporal data collected in the past and stored into an InfluxDB database, an open-source temporal database which is widely used because fast and highly available.
From the experimental point of view, Cyclops utilization has been stressed with a wide range of different workloads in order to observe the performance of the newly introduced function and the perceived unavailability time notwithstanding dynamic state migration and synchronization.
During the overall state migration procedure the database unavailability is limited to the deletions time of the database during the pre-copy phase. Depending on the dimension of the state to be migrated, the overall service migration can go from two millions of records to 100 millions of records. In any case, the service behavior is fully scalable with high performance, mainly limited by the InfluxDB internal operations to synchronize massive amount of new data, even if they do not affect the unavailability time but only the duration time of the migration which is a secondary metrics.
The whole code related to the service migration is available here on GitHub.